
What this template is for
Customer discovery interviews are only as useful as the synthesis that follows them. Teams that record ten interviews and then forget which insight came from which conversation lose the most valuable asset in a research programme: the ability to cite evidence when a product decision is questioned.
This template makes every interview a first-class Jira issue with:
- Structured context fields so you can filter and pivot across an entire research wave (e.g. “show me every interview where the pain point mentioned ‘onboarding’”).
- A consistent sub-task flow for scheduling, running, transcribing, synthesising, and sharing.
- A link from raw interview to product decision via the
relatedepic or feature-request issue.
When to use it
Use this template for any structured customer conversation that is part of a research initiative - generative discovery, jobs-to-be-done interviews, persona research, churn post-mortems. Skip it for casual hallway chats or unstructured sales calls; those belong in CRM notes.
How to set it up in Jira
Create a discovery research project, add the custom fields above to the Create Issue screen, and
configure an STM Issue Templates Executor to fire on Issue Created when the issue type is
Discovery Interview (or whatever you call yours). The sub-task list above will be created automatically
on every new interview, so researchers never forget the transcription or synthesis step. See
/stm-overview/ for the broader picture of how sub-task automation fits with discovery work.
Sub-task breakdown
- Schedule owns the calendar invite and consent form.
- Run is the live interview itself, time-boxed.
- Transcribe turns the recording into searchable text.
- Synthesise is where verbatim quotes become tagged insights in the research repo.
- Share ensures product, design, and engineering see the finding within 48 hours of the call.
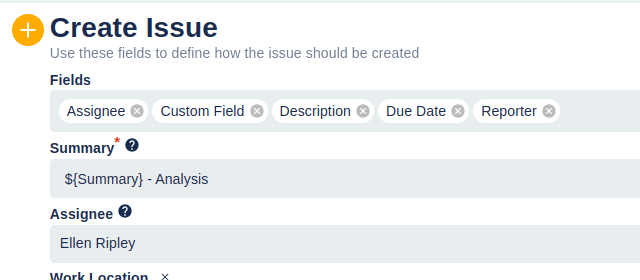
Fields to add to your Jira create screen
These are the fields a project admin should make sure exist on the Create Issue screen for this issue type (Project settings → Screens). Without these on the screen, reporters can't provide the information triage needs - and STM can't reference them either.
| Field | Example value | Required |
|---|---|---|
Summary | Discovery interview - Acme Corp - Director of Ops | Yes |
Interview Date (custom) | 2026-05-22 | Yes |
Interviewee Name (custom) | Jamie Patel | Yes |
Interviewee Role (custom) | Director of Operations | No |
Company / Segment (custom) | Mid-market SaaS, 200-500 employees | No |
Research Goal (custom) | Validate the onboarding-friction hypothesis | Yes |
Jobs-to-be-done Hypothesis (custom) | When onboarding a new team, I want to... | No |
Key Quotes (custom) | Verbatim quotes, one per line | No |
Pain Points Identified (custom) | Bulleted list | No |
Component/s | research, discovery | No |
Labels | discovery, q2-research, persona-ops | No |
Attachments | Recording, transcript, consent form | No |
Note on custom fields. STM currently supports up to 5 custom fields per template. You can add as many custom fields as you like to your Jira Create Issue screen - the 5-field limit only applies if you want STM to set or update those custom fields itself.
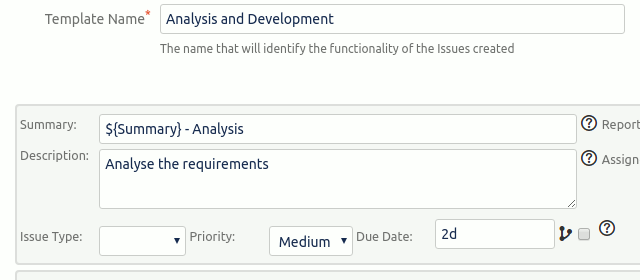
Sub-tasks STM creates automatically
Build an STM sub-task template containing the items below, then wire it to an On Create Issue Executor scoped to this issue type. Whenever a new issue of this type is created in the project, STM creates the full sub-task set in one step - with assignee, due date, and components inherited from the parent unless you override them.
- Schedule interview and send consent form
- Run interview using the agreed discussion guide
- Transcribe and tag the recording
- Synthesise findings into the research repo
- Share the insight summary with product and design
Common questions
What is a Jira customer discovery interview template?
It is a reusable Jira task that captures the structured context of a single customer conversation - interviewee details, research goal, hypothesis, verbatim quotes, and pain points - alongside the sub-tasks needed to schedule, transcribe, and synthesise the session. The point is to make raw interview data searchable and joinable across a research programme.
How do you run a customer discovery interview from Jira?
Create one Jira issue per interview using this template, populate the research goal and hypothesis before the call, then update the quotes and pain-point fields immediately after. Use sub-tasks for scheduling, transcription, and synthesis so each stage has a clear owner. Link the issue to the parent epic for the research initiative.
Should discovery interviews live in Jira or a separate research tool?
Most product teams keep transcripts and recordings in a dedicated repo (Dovetail, Notion, EnjoyHQ) and use Jira to track the workflow - schedule, run, synthesise, share. That gives you cycle-time metrics on research the same way you track engineering work, without forcing Jira to be a transcript store.
What custom fields belong on a discovery interview issue?
Interview date, interviewee name and role, company segment, research goal, jobs-to-be-done hypothesis, key quotes, and pain points identified. Add these to the Create Issue screen for your research project so every interview is logged consistently. Link a Custom Fields configuration for tag-style fields you want to filter on later.
Automate the sub-tasks with STM
STM Issue Templates saves the sub-task list above as a reusable template and creates them on every new issue of this type - via an Executor on issue creation, on status transition, or triggered manually from the issue's "Create bulk sub-tasks" menu. STM does not change the parent issue's create screen (that's a Jira project-settings job) but it removes the manual work of creating the sub-tasks every time.
Try STM on the Atlassian Marketplace ↗ See how STM templates are built →